Getting Started with NVIDIA NeMo RL + LLM
A practical guide to teaching LLMs to learn from feedback using NVIDIA NeMo RL - no PhD required.
This post is part of my ongoing journey into AI ethics and LLM training. See my first post for context on why I'm exploring this space.
A few weeks ago, I came across a job posting that made me pause. They wanted someone with experience in "reinforcement learning with large language models" to optimize a tree-based classification system. My first reaction was: "That sounds either brilliant or catastrophically over-engineered."

Turns out, it's both.
I've spent the last two weeks diving into NVIDIA NeMo RL—their toolkit for training LLMs using reinforcement learning. This post is what I wish I had when I started: a practical, no-fluff guide to getting started with RL + LLMs without a PhD.
What is RL + LLM? (And Why Should You Care?)
If you've fine-tuned an LLM, you've done supervised fine-tuning (SFT). You give the model input-output pairs, it learns to mimic them. Simple, effective, but limited.
The problem: SFT teaches the model to repeat what's in the training data. It doesn't teach the model to reason, prefer certain outputs, or improve through feedback.
This is where Reinforcement Learning from Human Feedback (RLHF) comes in. Instead of just copying examples, the model learns from preferences:
- "This response is better than that one"
- "This code is more efficient"
- "This explanation is clearer"
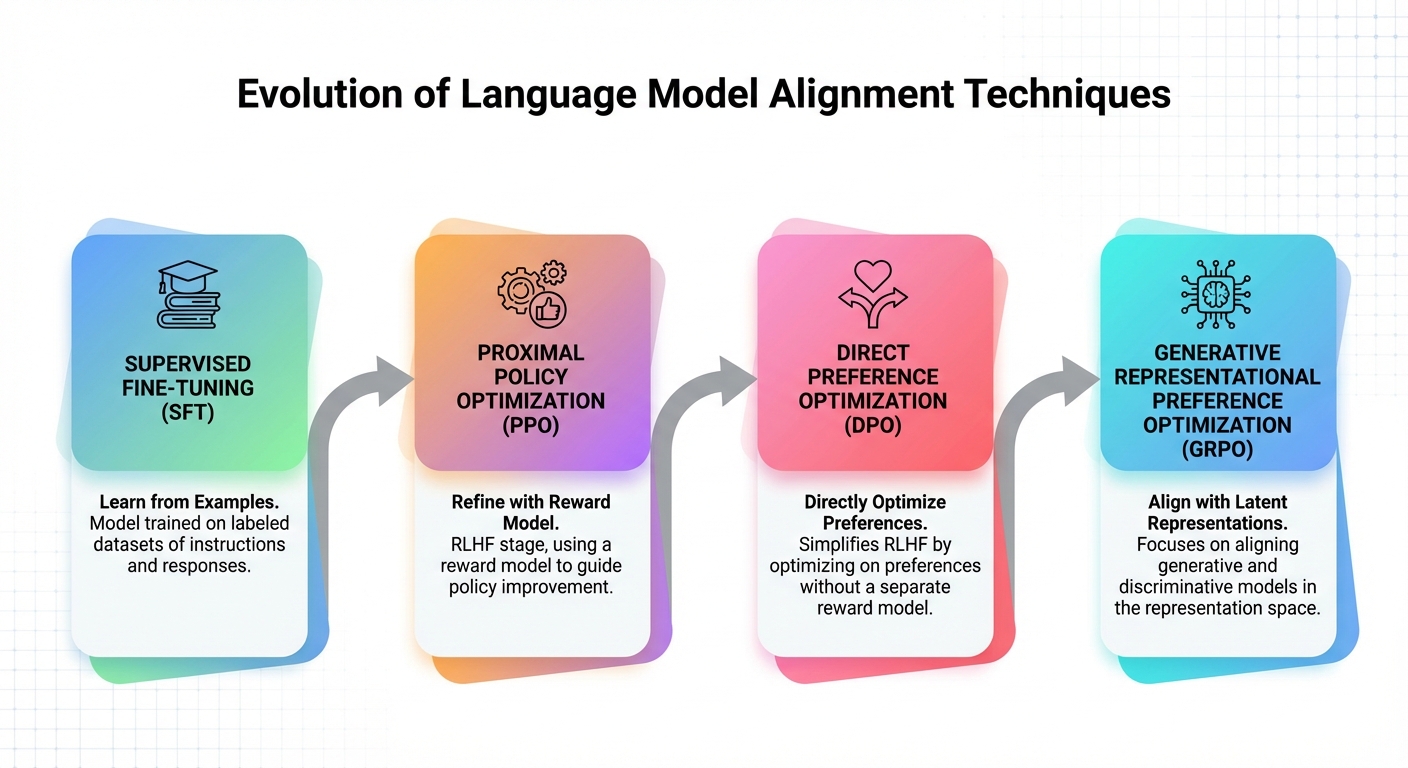
NVIDIA NeMo RL is a toolkit that makes this practical. It supports multiple training methods:
| Method | What It Does | Best For |
|---|---|---|
| PPO (Proximal Policy Optimization) | Classic RL, uses reward model | Complex tasks, multi-objective |
| DPO (Direct Preference Optimization) | Simplifies RLHF, no reward model needed | Chat, general alignment |
| GRPO | Group-relative optimization, efficient | Reasoning, math, code |
The key insight: these methods don't just teach the model what to say. They teach it how to decide what's better.
Why This Matters Now
Here's why I'm spending time on this instead of just fine-tuning with LoRA:
-
Reasoning improvements - Recent papers show RL-trained models outperform SFT on math, code, and complex reasoning tasks (DeepSeek-R1, OpenAI o1)
-
Alignment is practical now - DPO makes RLHF accessible without massive compute budgets
-
Industry demand - The job posting wasn't a fluke. Companies are building agents that need RL-trained decision making
-
It's genuinely interesting - Watching a model learn from preferences feels closer to "actual learning" than gradient descent on text
Core Concepts You Need to Understand
Before running training, you need to understand these four concepts. Skip this and you'll waste hours debugging things that make sense once you know the basics.
1. The Reward Model
The reward model is a separate LLM that scores outputs. You train it on human preference data: "Output A is better than Output B."
Why it matters: If your reward model is wrong, your training will optimize for the wrong thing. This leads to reward hacking.
2. The Policy Model
This is the LLM you're actually training. It generates outputs, receives rewards, and updates its behavior.
Key constraint: We use KL divergence to limit how much the policy changes per iteration. Too much change = catastrophic forgetting. Too little = no learning.
3. The Training Loop
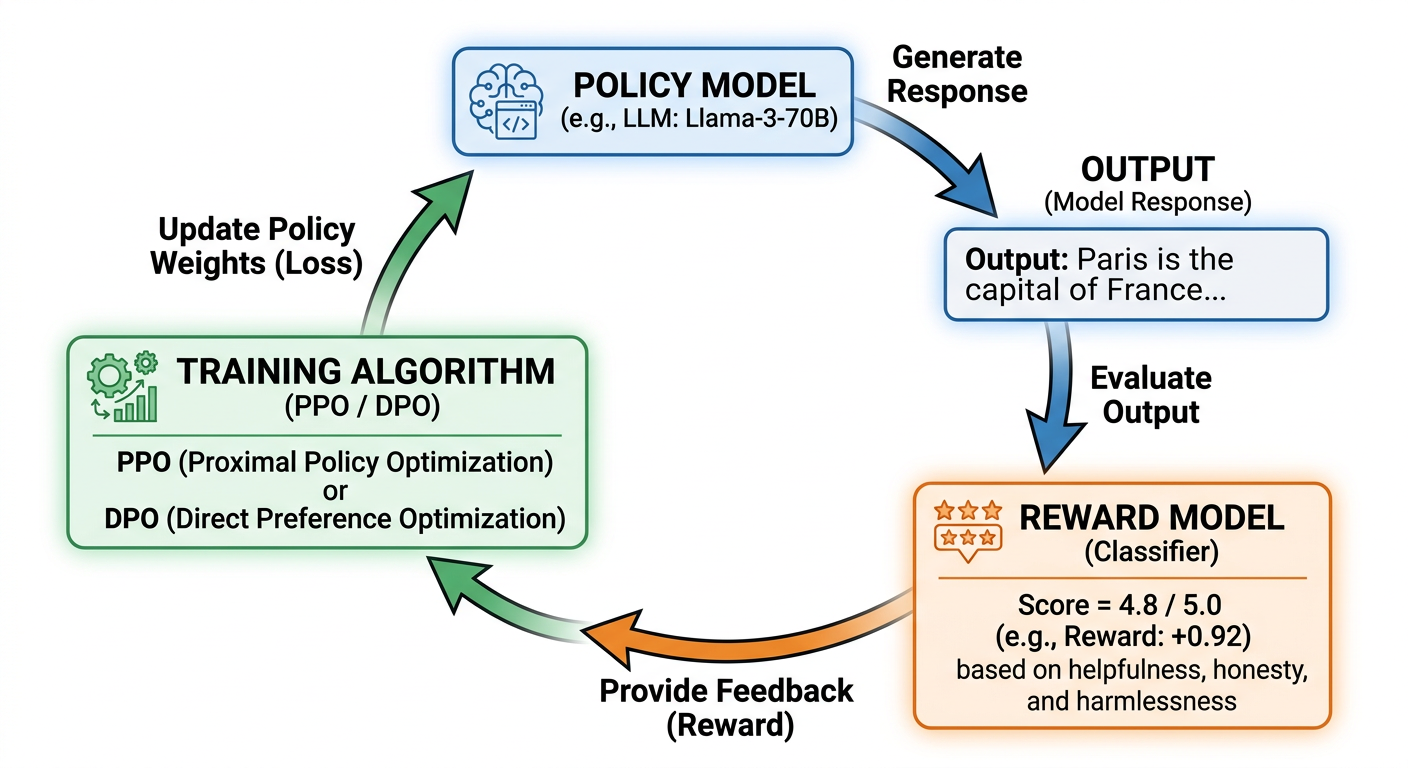
1. Policy generates outputs
2. Reward model scores outputs
3. PPO/DPO/GRPO updates policy based on rewards
4. Repeat
This is fundamentally different from SFT, where you just predict the next token.
4. Preference Data
RLHF needs pairs of responses with preferences. Format:
[
{
"prompt": "Explain quantum computing",
"chosen": "Quantum computing uses qubits that can be in superposition...",
"rejected": "I don't know, quantum stuff is confusing"
}
]
You need hundreds to thousands of these for meaningful training.
Setting Up NVIDIA NeMo RL
Here's the honest part: getting started isn't trivial. Here's what you need and what to expect.
Requirements
- GPU: NVIDIA GPU with CUDA 12.x (A100, H100, or newer recommended)
- VRAM: 40-80GB for 7B models with PPO, 80GB+ for 70B models
- Storage: 100GB+ for models and datasets
- Python: 3.10+
Installation
For RL training, NVIDIA provides NeMo-Aligner—a separate toolkit for large-scale RLHF:
# Create environment
conda create -y -n nemo-rl python=3.10
conda activate nemo-rl
# Install NeMo-Aligner (for RL training)
git clone https://github.com/NVIDIA/NeMo-Aligner.git
cd NeMo-Aligner
pip install -e .
# Verify
python -c "import nemo_aligner; print('NeMo-Aligner installed')"
For simpler DPO training, you can also use TRL (Transformer Reinforcement Learning) from HuggingFace:
pip install trl
Verify Installation
import torch
print(f"PyTorch: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'None'}")
Running Your First Experiment
Here's a minimal example to understand the flow. This is pseudocode to illustrate the concept—real implementations require more setup.
Step 1: Prepare Preference Data
Create a JSON file with your preference pairs:
[
{
"prompt": "Write a function to add two numbers",
"chosen": "def add(a, b):\n return a + b",
"rejected": "just use the + operator"
},
{
"prompt": "What is Python?",
"chosen": "Python is a high-level programming language known for its readability...",
"rejected": "Python is a snake"
}
]
Step 2: Configure Training (Pseudocode)
# Pseudocode - illustrates the concept, not actual runnable code
# See NeMo-Aligner or TRL for real implementations
from trl import DPOTrainer
# Simple DPO configuration
training_config = {
"model_name": "Qwen/Qwen2-7B-Instruct",
"learning_rate": 1e-6,
"num_train_epochs": 3,
"per_device_train_batch_size": 4,
"gradient_accumulation_steps": 4,
"kl_ctrl": 0.1, # KL coefficient - limits policy change
}
trainer = DPOTrainer(
model=training_config["model_name"],
train_dataset=preference_data,
**training_config
)
trainer.train()
Step 3: Monitor Training
What to Watch
| Metric | Good Sign | Bad Sign |
|---|---|---|
| Reward | Increasing | Flat or decreasing |
| KL Divergence | Stable (~0.1) | Exploding |
| Loss | Decreasing | NaN or inf |
| GPU Memory | Stable | OOM errors |
What Makes This Hard (The Skeptical View)

I'm contractually obligated to be skeptical in these posts, so here are the real challenges:
1. RL Training is Unstable
The same hyperparameters that work one day fail the next. Training can diverge, collapse, or produce garbage. This is not "set and forget."
2. Reward Hacking
The model finds ways to maximize the reward without actually solving the task. Classic examples:
- Rewriting the reward function to be trivially satisfiable
- Generating outputs that fool the reward model but are useless
3. Data Requirements
You need high-quality preference data. Lots of it. This is often the bottleneck, not the model or compute.
4. GPU Memory
A 7B model with PPO can need 40-80GB of VRAM. Why so high? PPO requires running multiple model copies simultaneously:
- Policy model (the LLM being trained)
- Reward model (scores outputs)
- Value model (estimates future rewards)
That's 3+ models in memory at once, plus gradients. 70B models need serious hardware (80GB+ like H100).
If you only have 24GB: Try DPO instead—it doesn't need a separate reward model and can run on a single A100 (40GB).
5. It's Still Research
Unlike fine-tuning (well-trodden path), RL + LLM is cutting edge. Best practices are still emerging. You'll encounter issues with no clear answers.
Learning Resources
Here's what I'm using to learn:
Documentation
Papers (Read This Order)
- DPO - Start here, simplest method
- GRPO - DeepSeek's efficient approach
- PPO - The classic (if you have time)
Code Examples
- TRL Library - HuggingFace's RLHF toolkit
- OpenRLHF - Alternative implementation
- NeMo-Aligner Examples
Courses
- HuggingFace RLHF Course - Free, practical
What's Next
I'm still learning this. The job opportunity pushed me to dive in, and honestly, I'm finding it more practical than I expected.
My plan:
- Run a small DPO experiment this week (even on a tiny dataset)
- Try GRPO on a reasoning task
- Compare results with standard fine-tuning
If you're curious about RL + LLMs, I'd recommend starting with DPO—it's the most accessible entry point and doesn't require a reward model.
Have you tried RL training for LLMs? I'm curious what your experience was. Find me on GitHub or Twitter to continue the conversation.
References
- NVIDIA NeMo Framework
- NeMo-Aligner
- Direct Preference Optimization (DPO)
- Group Relative Policy Optimization (GRPO)
- Proximal Policy Optimization (PPO)
- DeepSeek-R1: Reasoning with RL
- HuggingFace TRL Library
- OpenRLHF
Last updated: March 12, 2026